
PATS quantifies the strength of periodic oscillations embedded in duration data. The core idea is to:
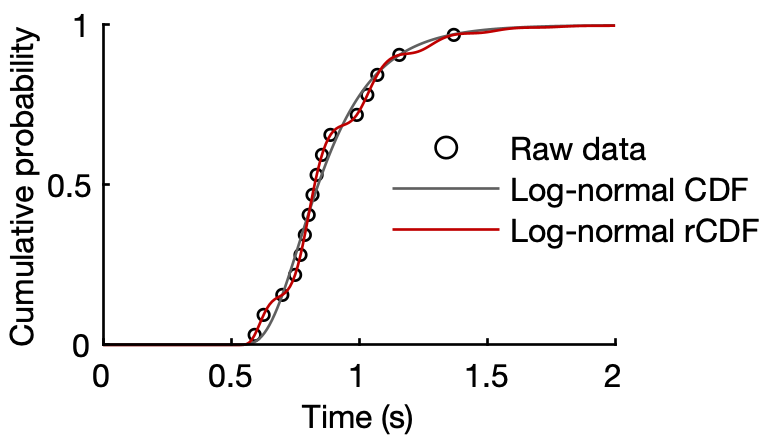
Due to its parametric approach, PATS remains effective even with small datasets. Figure 1 illustrates how an rCDF captures variance that a non-rhythmic CDF misses, using just 16 data points. Detailed information about PATS can be found in the following article:
DCANT Face Datasets are not your typical collection of datasets. Instead, they consist of image processing pipelines that generate masked face images from regular face images. The current collection includes pipelines compatible with the Chicago Face Database and the Karolinska Directed Emotional Faces. Below, you can compare grayscale face images with their final masked versions (Fig. 2) generated by a sample pipeline provided in the GitHub repository.

The datasets are used in the following article:
DCANT Random Stimulus Datasets are a collection of random shape and texture images and the code for generating them. The datasets are divided into two types: splash shapes and zebra blobs, with each type further categorized into two datasets—categorical and continuous. Splash shapes are simple silhouettes with contours defined by varying amplitudes at different radial frequencies. Zebra blobs are created using band-pass filtered white noise patterns that are windowed and saturated.
The categorical datasets consist of images sampled randomly from an object space, grouped into six subsets based on visual similarity. The continuous datasets feature images sampled continuously from a two-dimensional feature space. Sample images from the splash shape and zebra blob continuous datasets are shown in Figures 3 and 4.


The datasets are used in the following article: